SSD: Single Shot MultiBox Detector 学习笔记
概述
SSD是一种单阶段目标检测算法.所谓单阶段,是指只使用了一个deep neural network,而不是像faster-rcnn这种两阶段网络. 为什么有了faster-rcnn还要使用SSD? 最主要是慢... 两阶段网络虽然准确率高,但是在嵌入式等算力不足的设备上做inference速度非常感人,很难达到real time的要求. (实际业务上也是这样,公有云上的检测模型几乎都是faster-rcnn,而到了一些盒子之类的硬件设备,检测模型就全是SSD等single stage 模型了)
之前一直没有写SSD是因为相比faster rcnn的细节,SSD的问题似乎并不是很多.直到最近转模型的时候被FASF模型的一个细节卡了蛮久,因此决定还是记录一下.
基本概念
这部分描述SSD中涉及到的一些想法.
prior box
prior box的概念其实与faster-rcnn中anchor的概念是一样的,没有本质区别. 与faster-rcnn中的anchor不同的是,SSD会在多个feature map中的每个cell 都生成若干个prior_box.
对于一个特定的feature map,尺寸为m*n,假设有k个prior box,c种类别.
那么feature map的每个location会生成 k*(c+4) 个结果,其中c代表每一类的confidence. 4代表相对prior_box中心点的offset.
整个feature_map会生成 kmn(c+4) 个结果.
prior_box的参数选择,以及一些训练有关的细节可以参考原论文,这里不再赘述. 这里主要想强调一下和priox box有关的inference 细节. 主要是decode box的部分.
由于模型输出的bbox其实是相对每个prior_box的offset,不是真正的bbox,因此需要由网络输出的box_pred和prior box得到真正的bbox 坐标.这部分通常称为decode box,其实已经算是后处理部分了.
pytorch中decode box的代码如下:
1 variance1, variance2 = variance
2 cx = box_prior[:, :,
3 0] + box_pred[:, :, 0] * variance1 * box_prior[:, :, 2]
4 cy = box_prior[:, :,
5 1] + box_pred[:, :, 1] * variance1 * box_prior[:, :, 3]
6 w = box_prior[:, :, 2] + torch.exp(box_pred[:, :, 2] * variance2)
7 h = box_prior[:, :, 3] + torch.exp(box_pred[:, :, 3] * variance2)
8 x1 = cx - w / 2
9 y1 = cy - h / 2
10 x2 = w + x1
11 y2 = h + y1
12
不考虑variance的话,box_prior存储的四个数据按顺序分别为cx,cy,w,h 也就是prior_box的中心点坐标(cx,cy)以及宽和高.
而variance是一个原始paper中没有提到的实现细节. 按照 What is the purpose of the variances? 的说法,
Probably, the naming comes from the idea, that the ground truth bounding boxes are not always precise, in other words, they vary from image to image probably for the same object in the same position just because human labellers cannot ideally repeat themselves. Thus, the encoded values are some random values, and we want them to have unit variance that is why we divide by some value.
可以理解成一个用来消除由标注引入的随机因素的手段.
更多bbox encoding/decoding的内容可以参考 Bounding Box Encoding and Decoding in Object Detection
对应的cuda代码
1template <typename Dtype>
2__global__ void OneStageDecodeBBoxesSSDKernel_v2(const int nthreads, const Dtype* loc_data,
3 const Dtype* prior_data, const Dtype variance1, const Dtype variance2,
4 const int num_priors,const bool clip_bbox, Dtype* bbox_loc){
5
6 CUDA_KERNEL_LOOP(index, nthreads) {
7 // loc: Batch, num_priors, 4, 1
8 // proir: 1, num_priors, 4, 1
9 // nthreads = Batch * num_priors * 2
10 const int x_or_y = index % 2;
11 const int pri_idx = 4 * int( (index %(2*num_priors)) / 2) + x_or_y;
12 const int loc_idx = 4 * int(index /2) + x_or_y;
13 Dtype box0 = prior_data[pri_idx];
14 box0 = box0 + loc_data[loc_idx] * variance1 * box0;
15 Dtype box2 = prior_data[pri_idx + 2] * exp(variance2* loc_data[loc_idx+2]);
16 // box0就是prior box的中心点坐标x或者y,
17 // box2 就是prior box的w或者h.
18 // 下面的box0和box2复用了变量,但是实际上分别表示水平或者垂直方向的两个坐标.
19 box0 -= box2/2;
20 box2 += box0;
21 bbox_loc[loc_idx] = clip_bbox ? min(max(box0, 0.0),1.0): box0;
22 bbox_loc[loc_idx+2] = clip_bbox ? min(max(box2, 0.0),1.0): box2;
23 }
24}
25
如果涉及到部署,一个要注意的细节是,pytorch代码和caffe代码中prior_box 顺序的一致性.
loss
由于不(wo)涉(bu)及(hui)训练,loss不是关注的重点,简单说一句.
loss function是localization loss 和confidence loss 的加权和.
前半部分用来衡量bbox的loss,后半部分是分数的loss.
其中localization loss 如下图:
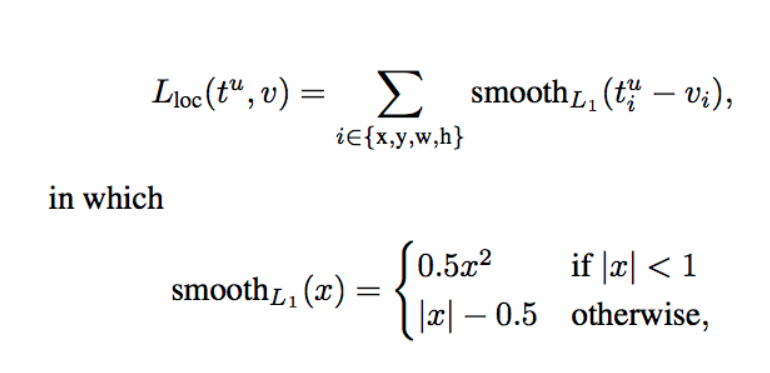
而confidence loss就是 softmax loss.
different scales of feature maps
神经网络越深的layer有着越大的感受野(receptive fileds),每个feature map cell包含着更抽象的信息. 我们可以用浅层的feature map来检测小物体,用深层的feture map来检测大物体.
这个想法后面会延伸到FPN,因此这里不详细讲了.
还是可以讲一讲的
我们可以直接看torchvision的SSD代码,预测的Module部分
1
2class PredictionConvolutions(nn.Module):
3 """
4 Convolutions to predict class scores and bounding boxes using lower and higher-level feature maps.
5 The bounding boxes (locations) are predicted as encoded offsets w.r.t each of the 8732 prior (default) boxes.
6 See 'cxcy_to_gcxgcy' in utils.py for the encoding definition.
7 The class scores represent the scores of each object class in each of the 8732 bounding boxes located.
8 A high score for 'background' = no object.
9 """
10
11 def __init__(self, n_classes):
12 """
13 :param n_classes: number of different types of objects
14 """
15 super(PredictionConvolutions, self).__init__()
16
17 self.n_classes = n_classes
18
19 # Number of prior-boxes we are considering per position in each feature map
20 n_boxes = {'conv4_3': 4,
21 'conv7': 6,
22 'conv8_2': 6,
23 'conv9_2': 6,
24 'conv10_2': 4,
25 'conv11_2': 4}
26 # 4 prior-boxes implies we use 4 different aspect ratios, etc.
27
28 # Localization prediction convolutions (predict offsets w.r.t prior-boxes)
29 self.loc_conv4_3 = nn.Conv2d(512, n_boxes['conv4_3'] * 4, kernel_size=3, padding=1)
30 self.loc_conv7 = nn.Conv2d(1024, n_boxes['conv7'] * 4, kernel_size=3, padding=1)
31 self.loc_conv8_2 = nn.Conv2d(512, n_boxes['conv8_2'] * 4, kernel_size=3, padding=1)
32 self.loc_conv9_2 = nn.Conv2d(256, n_boxes['conv9_2'] * 4, kernel_size=3, padding=1)
33 self.loc_conv10_2 = nn.Conv2d(256, n_boxes['conv10_2'] * 4, kernel_size=3, padding=1)
34 self.loc_conv11_2 = nn.Conv2d(256, n_boxes['conv11_2'] * 4, kernel_size=3, padding=1)
35
36 # Class prediction convolutions (predict classes in localization boxes)
37 self.cl_conv4_3 = nn.Conv2d(512, n_boxes['conv4_3'] * n_classes, kernel_size=3, padding=1)
38 self.cl_conv7 = nn.Conv2d(1024, n_boxes['conv7'] * n_classes, kernel_size=3, padding=1)
39 self.cl_conv8_2 = nn.Conv2d(512, n_boxes['conv8_2'] * n_classes, kernel_size=3, padding=1)
40 self.cl_conv9_2 = nn.Conv2d(256, n_boxes['conv9_2'] * n_classes, kernel_size=3, padding=1)
41 self.cl_conv10_2 = nn.Conv2d(256, n_boxes['conv10_2'] * n_classes, kernel_size=3, padding=1)
42 self.cl_conv11_2 = nn.Conv2d(256, n_boxes['conv11_2'] * n_classes, kernel_size=3, padding=1)
43
44 # Initialize convolutions' parameters
45 self.init_conv2d()
46
47 def init_conv2d(self):
48 """
49 Initialize convolution parameters.
50 """
51 for c in self.children():
52 if isinstance(c, nn.Conv2d):
53 nn.init.xavier_uniform_(c.weight)
54 nn.init.constant_(c.bias, 0.)
55
56 def forward(self, conv4_3_feats, conv7_feats, conv8_2_feats, conv9_2_feats, conv10_2_feats, conv11_2_feats):
57 """
58 Forward propagation.
59 :param conv4_3_feats: conv4_3 feature map, a tensor of dimensions (N, 512, 38, 38)
60 :param conv7_feats: conv7 feature map, a tensor of dimensions (N, 1024, 19, 19)
61 :param conv8_2_feats: conv8_2 feature map, a tensor of dimensions (N, 512, 10, 10)
62 :param conv9_2_feats: conv9_2 feature map, a tensor of dimensions (N, 256, 5, 5)
63 :param conv10_2_feats: conv10_2 feature map, a tensor of dimensions (N, 256, 3, 3)
64 :param conv11_2_feats: conv11_2 feature map, a tensor of dimensions (N, 256, 1, 1)
65 :return: 8732 locations and class scores (i.e. w.r.t each prior box) for each image
66 """
67 batch_size = conv4_3_feats.size(0)
68
69 # Predict localization boxes' bounds (as offsets w.r.t prior-boxes)
70 l_conv4_3 = self.loc_conv4_3(conv4_3_feats) # (N, 16, 38, 38)
71 l_conv4_3 = l_conv4_3.permute(0, 2, 3,
72 1).contiguous() # (N, 38, 38, 16), to match prior-box order (after .view())
73 # (.contiguous() ensures it is stored in a contiguous chunk of memory, needed for .view() below)
74 l_conv4_3 = l_conv4_3.view(batch_size, -1, 4) # (N, 5776, 4), there are a total 5776 boxes on this feature map
75
76 l_conv7 = self.loc_conv7(conv7_feats) # (N, 24, 19, 19)
77 l_conv7 = l_conv7.permute(0, 2, 3, 1).contiguous() # (N, 19, 19, 24)
78 l_conv7 = l_conv7.view(batch_size, -1, 4) # (N, 2166, 4), there are a total 2116 boxes on this feature map
79
80 l_conv8_2 = self.loc_conv8_2(conv8_2_feats) # (N, 24, 10, 10)
81 l_conv8_2 = l_conv8_2.permute(0, 2, 3, 1).contiguous() # (N, 10, 10, 24)
82 l_conv8_2 = l_conv8_2.view(batch_size, -1, 4) # (N, 600, 4)
83
84 l_conv9_2 = self.loc_conv9_2(conv9_2_feats) # (N, 24, 5, 5)
85 l_conv9_2 = l_conv9_2.permute(0, 2, 3, 1).contiguous() # (N, 5, 5, 24)
86 l_conv9_2 = l_conv9_2.view(batch_size, -1, 4) # (N, 150, 4)
87
88 l_conv10_2 = self.loc_conv10_2(conv10_2_feats) # (N, 16, 3, 3)
89 l_conv10_2 = l_conv10_2.permute(0, 2, 3, 1).contiguous() # (N, 3, 3, 16)
90 l_conv10_2 = l_conv10_2.view(batch_size, -1, 4) # (N, 36, 4)
91
92 l_conv11_2 = self.loc_conv11_2(conv11_2_feats) # (N, 16, 1, 1)
93 l_conv11_2 = l_conv11_2.permute(0, 2, 3, 1).contiguous() # (N, 1, 1, 16)
94 l_conv11_2 = l_conv11_2.view(batch_size, -1, 4) # (N, 4, 4)
95
96 # Predict classes in localization boxes
97 c_conv4_3 = self.cl_conv4_3(conv4_3_feats) # (N, 4 * n_classes, 38, 38)
98 c_conv4_3 = c_conv4_3.permute(0, 2, 3,
99 1).contiguous() # (N, 38, 38, 4 * n_classes), to match prior-box order (after .view())
100 c_conv4_3 = c_conv4_3.view(batch_size, -1,
101 self.n_classes) # (N, 5776, n_classes), there are a total 5776 boxes on this feature map
102
103 c_conv7 = self.cl_conv7(conv7_feats) # (N, 6 * n_classes, 19, 19)
104 c_conv7 = c_conv7.permute(0, 2, 3, 1).contiguous() # (N, 19, 19, 6 * n_classes)
105 c_conv7 = c_conv7.view(batch_size, -1,
106 self.n_classes) # (N, 2166, n_classes), there are a total 2116 boxes on this feature map
107
108 c_conv8_2 = self.cl_conv8_2(conv8_2_feats) # (N, 6 * n_classes, 10, 10)
109 c_conv8_2 = c_conv8_2.permute(0, 2, 3, 1).contiguous() # (N, 10, 10, 6 * n_classes)
110 c_conv8_2 = c_conv8_2.view(batch_size, -1, self.n_classes) # (N, 600, n_classes)
111
112 c_conv9_2 = self.cl_conv9_2(conv9_2_feats) # (N, 6 * n_classes, 5, 5)
113 c_conv9_2 = c_conv9_2.permute(0, 2, 3, 1).contiguous() # (N, 5, 5, 6 * n_classes)
114 c_conv9_2 = c_conv9_2.view(batch_size, -1, self.n_classes) # (N, 150, n_classes)
115
116 c_conv10_2 = self.cl_conv10_2(conv10_2_feats) # (N, 4 * n_classes, 3, 3)
117 c_conv10_2 = c_conv10_2.permute(0, 2, 3, 1).contiguous() # (N, 3, 3, 4 * n_classes)
118 c_conv10_2 = c_conv10_2.view(batch_size, -1, self.n_classes) # (N, 36, n_classes)
119
120 c_conv11_2 = self.cl_conv11_2(conv11_2_feats) # (N, 4 * n_classes, 1, 1)
121 c_conv11_2 = c_conv11_2.permute(0, 2, 3, 1).contiguous() # (N, 1, 1, 4 * n_classes)
122 c_conv11_2 = c_conv11_2.view(batch_size, -1, self.n_classes) # (N, 4, n_classes)
123
124 # A total of 8732 boxes
125 # Concatenate in this specific order (i.e. must match the order of the prior-boxes)
126 locs = torch.cat([l_conv4_3, l_conv7, l_conv8_2, l_conv9_2, l_conv10_2, l_conv11_2], dim=1) # (N, 8732, 4)
127 classes_scores = torch.cat([c_conv4_3, c_conv7, c_conv8_2, c_conv9_2, c_conv10_2, c_conv11_2],
128 dim=1) # (N, 8732, n_classes)
129
130 return locs, classes_scores
131
132
位置的预测和分数的预测可以分两部分来看
1
2 self.loc_conv4_3 = nn.Conv2d(512, n_boxes['conv4_3'] * 4, kernel_size=3, padding=1)
3 # n_boxes里面是不同的feature_map中每个位置的prior box的数量 n_boxes['conv4_3'] * 4是因为bbox有四个坐标(以offset的形式)
4
5 # conv4_3_feats:(N, 512, 38, 38)
6 # Predict localization boxes' bounds (as offsets w.r.t prior-boxes)
7 l_conv4_3 = self.loc_conv4_3(conv4_3_feats) # (N, 16, 38, 38)
8 # shape中的16的含义是,每个位置有4个prior box,每个box有4个坐标。 这16个值坐落在16个channel上
9 l_conv4_3 = l_conv4_3.permute(0, 2, 3,
10 1).contiguous() # (N, 38, 38, 16), to match prior-box order (after .view())
11 # (.contiguous() ensures it is stored in a contiguous chunk of memory, needed for .view() below)
12 l_conv4_3 = l_conv4_3.view(batch_size, -1, 4) # (N, 5776, 4), there are a total 5776 boxes on this
13
14 # 5776个box是 38*38的feature map上每个位置上有4个。 38*38*4=5776
15
然后是分数的预测,我们注意到对于feature map上每个位置的每个prior box都有一个conf 注意这里对于每个prior box,虽然有多个类别的分数,但是他们的位置预测只有一组值,这里和frcnn是不同的
1 # Class prediction convolutions (predict classes in localization boxes)
2 self.cl_conv4_3 = nn.Conv2d(512, n_boxes['conv4_3'] * n_classes, kernel_size=3, padding=1)
3
4 # Predict classes in localization boxes
5 c_conv4_3 = self.cl_conv4_3(conv4_3_feats) # (N, 4 * n_classes, 38, 38)
6 c_conv4_3 = c_conv4_3.permute(0, 2, 3,
7 1).contiguous() # (N, 38, 38, 4 * n_classes), to match prior-box order (after .view())
8 c_conv4_3 = c_conv4_3.view(batch_size, -1,
9 self.n_classes) # (N, 5776, n_classes), there are a total 5776 boxes on this feature map
10
11
总结
- 使用不同scale的feature map来预测,提升了准确度。
- 预测bbox使用预测默认bbox(prior box)的offset的方式,使得使用small conv filters即可达到不错的效果,减少了计算。