caffe 源码学习笔记(2) Layer
layer 整体介绍
layer是模型计算的基本单元 类似于pytorch或者其他深度学习框架的op layer中的数据流向为,输入若干个blob,称之为"bottom blob",然后经过layer的计算,输出若干个blob,称之为"top blob"
也就是数据是从“bottom”流向“top”
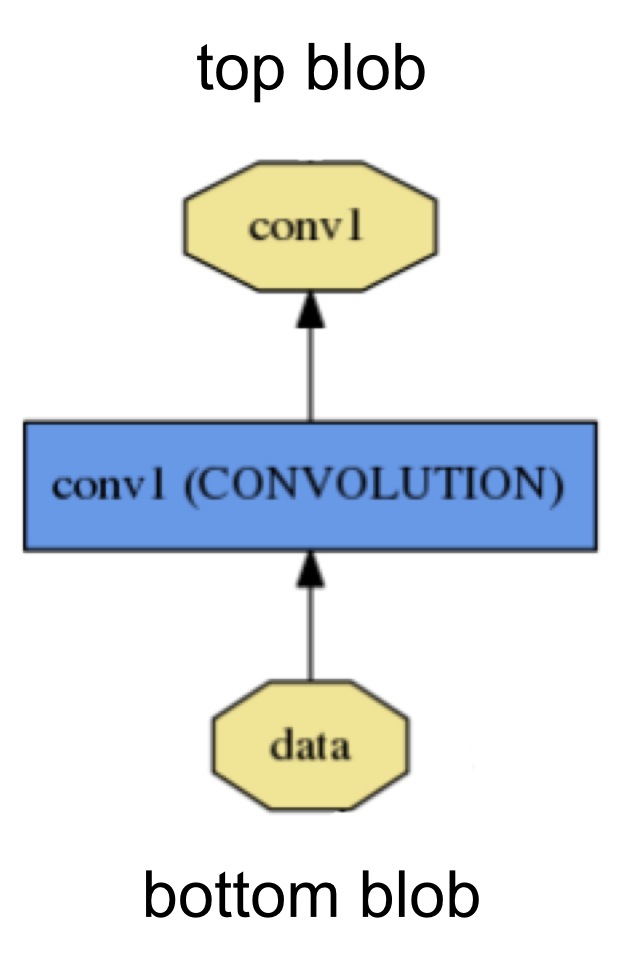
layer通常会进行两种计算,forward和backward
forward是指,根据bottom blob计算得到top blob backward是指,根据top blob的结果和参数值计算得到的gradient,回传给前面的layer.
layer 实现细节
layer作为一个base class,实现了所有layer都需要的common的部分。 比如:
1 /**
2 * @brief Implements common layer setup functionality.
3 *
4 * @param bottom the preshaped input blobs
5 * @param top
6 * the allocated but unshaped output blobs, to be shaped by Reshape
7 *
8 * Checks that the number of bottom and top blobs is correct.
9 * Calls LayerSetUp to do special layer setup for individual layer types,
10 * followed by Reshape to set up sizes of top blobs and internal buffers.
11 * Sets up the loss weight multiplier blobs for any non-zero loss weights.
12 * This method may not be overridden.
13 */
14 void SetUp(const vector<Blob<Dtype>*>& bottom,
15 const vector<Blob<Dtype>*>& top) {
16 CheckBlobCounts(bottom, top);
17 LayerSetUp(bottom, top);
18 Reshape(bottom, top);
19 SetLossWeights(top);
20 }
SetUp可以理解成layer的初始化函数。
这部分代码比较容易看懂,可以说的不多。 值得注意的是,下面这段代码:
1 /** @brief Using the CPU device, compute the layer output. */
2 virtual void Forward_cpu(const vector<Blob<Dtype>*>& bottom,
3 const vector<Blob<Dtype>*>& top) = 0;
4 /**
5 * @brief Using the GPU device, compute the layer output.
6 * Fall back to Forward_cpu() if unavailable.
7 */
8 virtual void Forward_gpu(const vector<Blob<Dtype>*>& bottom,
9 const vector<Blob<Dtype>*>& top) {
10 // LOG(WARNING) << "Using CPU code as backup.";
11 return Forward_cpu(bottom, top);
12 }
13
只有cpu上的forward(backward同理)被定义成纯虚函数,而base class上gpu上的forward被定义调用基类的forward_cpu
这样做使得每个layer必须定义自己的Forward_cpu函数,同时使得某个layer没有自己的Forward_gpu函数时,会fall back到相应的cpu版本。
layer对blob的限制
2020.05.03补充:
看了一些layer的具体实现后,我们发现有一个信息我们是没办法通过proto看出来的. 就是一个layer的输出和输出的blob的个数.
caffe的做法是在layer的基类中定义ExactNumBottomBlobs(), MinTopBlobs() 等. 可以限制bottom blob和top blob的范围或者具体的值. 也可以通过 EqualNumBottomTopBlobs() 来控制bottom和top blob的个数一致.
1 /**
2 * @brief Returns the exact number of bottom blobs required by the layer,
3 * or -1 if no exact number is required.
4 *
5 * This method should be overridden to return a non-negative value if your
6 * layer expects some exact number of bottom blobs.
7 */
8 virtual inline int ExactNumBottomBlobs() const { return -1; }
9 /**
10 * @brief Returns the minimum number of bottom blobs required by the layer,
11 * or -1 if no minimum number is required.
12 *
13 * This method should be overridden to return a non-negative value if your
14 * layer expects some minimum number of bottom blobs.
15 */
16 virtual inline int MinBottomBlobs() const { return -1; }
17 /**
18 * @brief Returns the maximum number of bottom blobs required by the layer,
19 * or -1 if no maximum number is required.
20 *
21 * This method should be overridden to return a non-negative value if your
22 * layer expects some maximum number of bottom blobs.
23 */
24 virtual inline int MaxBottomBlobs() const { return -1; }
25 /**
26 * @brief Returns the exact number of top blobs required by the layer,
27 * or -1 if no exact number is required.
28 *
29 * This method should be overridden to return a non-negative value if your
30 * layer expects some exact number of top blobs.
31 */
32 virtual inline int ExactNumTopBlobs() const { return -1; }
33 /**
34 * @brief Returns the minimum number of top blobs required by the layer,
35 * or -1 if no minimum number is required.
36 *
37 * This method should be overridden to return a non-negative value if your
38 * layer expects some minimum number of top blobs.
39 */
40 virtual inline int MinTopBlobs() const { return -1; }
41 /**
42 * @brief Returns the maximum number of top blobs required by the layer,
43 * or -1 if no maximum number is required.
44 *
45 * This method should be overridden to return a non-negative value if your
46 * layer expects some maximum number of top blobs.
47 */
48 virtual inline int MaxTopBlobs() const { return -1; }
49 /**
50 * @brief Returns true if the layer requires an equal number of bottom and
51 * top blobs.
52 *
53 * This method should be overridden to return true if your layer expects an
54 * equal number of bottom and top blobs.
55 */
56 virtual inline bool EqualNumBottomTopBlobs() const { return false; }
57
然后具体的layer再override掉需要限制的部分.
然后在layer SetUp的时候,会去 check这些blob的个数
1
2
3/**
4 * Called by the parent Layer's SetUp to check that the number of bottom
5 * and top Blobs provided as input match the expected numbers specified by
6 * the {ExactNum,Min,Max}{Bottom,Top}Blobs() functions.
7 */
8 virtual void CheckBlobCounts(const vector<Blob<Dtype>*>& bottom,
9 const vector<Blob<Dtype>*>& top) {
10 if (ExactNumBottomBlobs() >= 0) {
11 CHECK_EQ(ExactNumBottomBlobs(), bottom.size())
12 << type() << " Layer takes " << ExactNumBottomBlobs()
13 << " bottom blob(s) as input.";
14 }
15 if (MinBottomBlobs() >= 0) {
16 CHECK_LE(MinBottomBlobs(), bottom.size())
17 << type() << " Layer takes at least " << MinBottomBlobs()
18 << " bottom blob(s) as input.";
19 }
20 if (MaxBottomBlobs() >= 0) {
21 CHECK_GE(MaxBottomBlobs(), bottom.size())
22 << type() << " Layer takes at most " << MaxBottomBlobs()
23 << " bottom blob(s) as input.";
24 }
25 if (ExactNumTopBlobs() >= 0) {
26 CHECK_EQ(ExactNumTopBlobs(), top.size())
27 << type() << " Layer produces " << ExactNumTopBlobs()
28 << " top blob(s) as output.";
29 }
30 if (MinTopBlobs() >= 0) {
31 CHECK_LE(MinTopBlobs(), top.size())
32 << type() << " Layer produces at least " << MinTopBlobs()
33 << " top blob(s) as output.";
34 }
35 if (MaxTopBlobs() >= 0) {
36 CHECK_GE(MaxTopBlobs(), top.size())
37 << type() << " Layer produces at most " << MaxTopBlobs()
38 << " top blob(s) as output.";
39 }
40 if (EqualNumBottomTopBlobs()) {
41 CHECK_EQ(bottom.size(), top.size())
42 << type() << " Layer produces one top blob as output for each "
43 << "bottom blob input.";
44 }
45 }
46
然后还有个问题,就是如果有多个blob,怎么规定顺序呢? 目前来看,是没有什么办法强制规定的,这部分主要取决于layer实现作者的意愿. 好在这种不同blob的含义不同的layer不是特别多..
layer factory 介绍
等待补充
layor factory 可以用来registry layers.
1 typedef shared_ptr<Layer<Dtype> > (*Creator)(const LayerParameter&);
2 typedef std::map<string, Creator> CreatorRegistry;
我们可以看到LayerRegistry class template 定义了两个类型 一个是函数指针Creator,类型为
1 shared_ptr<Layer<Dtype> > (const LayerParameter&);
另一个是CreatorRegistry,建立起了某种映射。
下面我们看到成员函数Registry
1 static CreatorRegistry& Registry() {
2 static CreatorRegistry* g_registry_ = new CreatorRegistry();
3 return *g_registry_;
4 }
5
这里用到了单例模式(Singleton),使得整个class只有唯一的一个CreatorRegistry实例
单例模式可以参考这里
接下来我们看到成员函数AddCreator
1 // Adds a creator.
2 static void AddCreator(const string& type, Creator creator) {
3 CreatorRegistry& registry = Registry();
4 // layer type需要在 CreatorRegistry 表中唯一
5 CHECK_EQ(registry.count(type), 0)
6 << "Layer type " << type << " already registered.";
7 registry[type] = creator;
8 }
此时我们知道,CreatorRegistry的这个table是用来存layer type到相应layer的creator的映射关系的。
接下来我们看到成员函数CreateLayer,见注释
1 // Get a layer using a LayerParameter.
2 static shared_ptr<Layer<Dtype> > CreateLayer(const LayerParameter& param) {
3 if (Caffe::root_solver()) {
4 LOG(INFO) << "Creating layer " << param.name();
5 }
6 const string& type = param.type();
7 CreatorRegistry& registry = Registry();
8 CHECK_EQ(registry.count(type), 1) << "Unknown layer type: " << type
9 << " (known types: " << LayerTypeListString() << ")";
10 // registry[type]返回一个creator
11 // creator是第一个 函数指针,类型为 shared_ptr<Layer<Dtype> > (const LayerParameter&)
12 // 因此最终的返回值类型为shared_ptr<Layer<Dtype> >,也就是layer的指针。
13 return registry[type](param);
14 }
15
接下来是成员函数LayerTypeList,作用是列出目前注册过的所有layer type的名称。
1 static vector<string> LayerTypeList() {
2 CreatorRegistry& registry = Registry();
3 vector<string> layer_types;
4 // 在模板实例化之前,编译器无法知道scope operator(::)后是"static members“还是”type members“
5 // 默认情况下,scope operator后接的是static merbers
6 // 所以这里需要使用typename 关键词,显式告诉编译器,后面是一个type name
7 for (typename CreatorRegistry::iterator iter = registry.begin();
8 iter != registry.end(); ++iter) {
9 layer_types.push_back(iter->first);
10 }
11 return layer_types;
12 }
13
值得注意的是此处typename 关键词的使用,原因见注释。
最后可以看到两个宏定义
1
2#define REGISTER_LAYER_CREATOR(type, creator) \
3 static LayerRegisterer<float> g_creator_f_##type(#type, creator<float>); \
4 static LayerRegisterer<double> g_creator_d_##type(#type, creator<double>) \
5
6#define REGISTER_LAYER_CLASS(type) \
7 template <typename Dtype> \
8 shared_ptr<Layer<Dtype> > Creator_##type##Layer(const LayerParameter& param) \
9 { \
10 return shared_ptr<Layer<Dtype> >(new type##Layer<Dtype>(param)); \
11 } \
12 REGISTER_LAYER_CREATOR(type, Creator_##type##Layer)
13
对应了两种register a layer 的方式
一种是可以直接通过layer的constructor来创建,另一种是通过一个其他的creator函数来创建。
从这两个宏定义中可以看出,REGISTER_LAYER_CREATOR 是真正做工作的部分。 REGISTER_LAYER_CLASS 可以看做没有提供creator的特殊情况,此时先通过layer的constructor来定义一个creator,再去调用REGISTER_LAYER_CREATOR
可能值得一提的是宏定义中## 符号,称为 macro operator 作用是将两个token,合成一个token
1<token> ## <token>
我们观察layer_factory.cpp中,发现使用其他creator来创建layer的一种情况是,某个layer可能有cudnn对应的实现。要根据是否有use_cudnn的编译选项,来返回一个cudnn版本的layer还是普通版本的layer.
比如下面这个conv layer
1
2// Get convolution layer according to engine.
3template <typename Dtype>
4shared_ptr<Layer<Dtype> > GetConvolutionLayer(
5 const LayerParameter& param) {
6 ConvolutionParameter conv_param = param.convolution_param();
7 ConvolutionParameter_Engine engine = conv_param.engine();
8#ifdef USE_CUDNN
9 bool use_dilation = false;
10 for (int i = 0; i < conv_param.dilation_size(); ++i) {
11 if (conv_param.dilation(i) > 1) {
12 use_dilation = true;
13 }
14 }
15#endif
16 if (engine == ConvolutionParameter_Engine_DEFAULT) {
17 engine = ConvolutionParameter_Engine_CAFFE;
18#ifdef USE_CUDNN
19 if (!use_dilation) {
20 engine = ConvolutionParameter_Engine_CUDNN;
21 }
22#endif
23 }
24 if (engine == ConvolutionParameter_Engine_CAFFE) {
25 return shared_ptr<Layer<Dtype> >(new ConvolutionLayer<Dtype>(param));
26#ifdef USE_CUDNN
27 } else if (engine == ConvolutionParameter_Engine_CUDNN) {
28 if (use_dilation) {
29 LOG(FATAL) << "CuDNN doesn't support the dilated convolution at Layer "
30 << param.name();
31 }
32 return shared_ptr<Layer<Dtype> >(new CuDNNConvolutionLayer<Dtype>(param));
33#endif
34 } else {
35 LOG(FATAL) << "Layer " << param.name() << " has unknown engine.";
36 throw; // Avoids missing return warning
37 }
38}
39
40REGISTER_LAYER_CREATOR(Convolution, GetConvolutionLayer);
Posts in this Series
- caffe 源码阅读笔记
- [施工中]caffe 源码学习笔记(11) softmax
- caffe 源码学习笔记(11) argmax layer
- caffe 源码学习笔记(10) eltwise layer
- caffe 源码学习笔记(9) reduce layer
- caffe 源码学习笔记(8) loss function
- caffe 源码学习笔记(7) slice layer
- caffe 源码学习笔记(6) reshape layer
- caffe 源码学习笔记(5) 卷积
- caffe 源码学习笔记(4) 激活函数
- caffe 源码学习笔记(3) Net
- caffe 源码学习笔记(2) Layer
- caffe 源码学习笔记(1) Blob