Faster Rcnn 目标检测算法
背景
2019年对了好几次faster rcnn,第一次是赛事之窗项目和北京的同事,对齐sdk和训练的实现。 第二次是被tensorRT4和tensorRT5之间默认参数不一致的问题坑了一下。 第三次是被caffe proto中roi align 的默认参数坑了。
虽然debug了这么多次,踩了一堆坑,但是一段时间不用,细节就会慢慢不记得了。因此来记录一下。
faster rcnn,是一种"two stage"的目标检测算法。
所谓"two stage",是说在实际进行目标检测之前,先会通过某种"region proposals" algorithm,来获得一定数量的RoI(Regions of Interest),我们下一阶段要检测的obejct有极大可能被包含在这些RoI. 这种"Region based"的方法是对基于"sliding windows"方法的极大改进,因为不需要遍历每一个可能的位置以及crop大小,只需要对这些RoI进行检测,有效地减小了计算量。
下面简单说一下这一类"Region based"方法的历史脉络
rcnn
RCNN的做法是通过一种传统方法"selective search"来得到若干RoI,然后把每一个RoI,后面接CNN进行后续的检测。 显然,这个方法的问题在于计算量非常大。
selective search的策略是,既然是不知道尺度是怎样的,那我们就尽可能遍历所有的尺度,但是不同于暴力穷举,我们可以先得到小尺度的区域,然后一次次合并得到大的尺寸.
fast rcnn
明眼人可以看出,rcnn计算量过大的原因之一是做了非常多的重复计算。
因此fast rcnn做的改进是,与其把每一个通过"selective search"得到的RoI在原图上crop出来送进CNN,不如先让整张图过一段CNN,然后把通过"selective search"在原图上得到的RoI先映射到这段CNN的某个conv feature map. 相当于这部分CNN只做了一次,与RoI数量无关,极大地减小了计算量。
faster rcnn
终于轮到主角登场了。 fast rcnn极大提高了检测的速度。 然后发现,速度的瓶颈已经不在后续的检测部分了,而是在于“region proposals” algorithm.
于是,faster-rcnn提出"Region proposal network"来替代"selective search",进一步提高了检测速度。
放一张结构图,非常清楚。
Region proposal network(RPN)
anchor
介绍RPN网络首先就要介绍一下anchor.
(被坑过一次,某个足球项目上,training和inference用的anchor竟然是不一致的。。)
其实anchor这个概念很简单,用大白话说就是,根据要检测的物体的形状(高矮胖瘦等),预先 设置一些不同尺寸(高矮胖瘦)的粗略的框,然后对这些框做一个二分类,判断前景还是背景,同时做bbox regression 来微调坐标,最终得到proposals.
设置anchor的思路其实就是修改了proposals的默认位置为生成的anchors的位置。对这些anchors进行微调总要比从零开始生成容易得多。
要注意的是,anchors是在进入网络前预先生成的。 实际项目中,通常设置长宽比为[1:1,2:1,1:2]三种比例,然后通过 generate_anchors.py 来生成anchors.
值得强调的是,anchor的生成是与图像内容无关的.无论图像内容是什么,生成的anchor都是固定的,而RPN网络的目标就是去学习哪些anchor是好的anchor,以及学习到一组"regression coefficients"来用在好的anchor上,从而变成更好的anchor.
RPN 网络结构
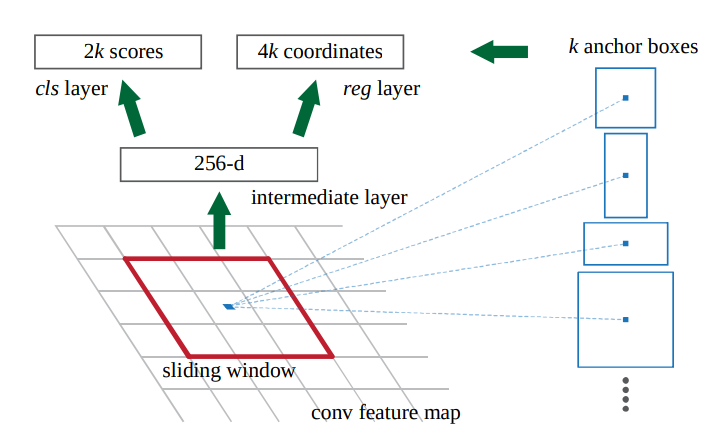
最下面的conv feature map是经过一段CNN得到的,这部分和fast rcnn是类似的。
这一段CNN是RPN和后面的detector共用的。
然后用一个n*n的滑动窗口(原paper中用的3*3,其实就是做了个3*3的卷积),得到256维的feature(是因为这个conv feature map的深度是256). 然后对于cls和reg 分别做两个fc,输入分别为2和4. 由于一共有k个anchor,因此一共输入2k个scores和4k个coordinates.
最初我的一个疑惑是,为什么这里要做softmax二分类呢? 为什么要关心背景的置信度呢?
原文中的解释是:
For simplicity we implement the cls layer as a two-class softmax layer. Alternatively, one may use logistic regression to produce k scores.
实际上,torchvision中rpn的时间就是使用了logistic来计算k个score. 代码如下:
1
2
3class RPNHead(nn.Module):
4 """
5 Adds a simple RPN Head with classification and regression heads
6 Arguments:
7 in_channels (int): number of channels of the input feature
8 num_anchors (int): number of anchors to be predicted
9 """
10
11 def __init__(self, in_channels, num_anchors):
12 super(RPNHead, self).__init__()
13 self.conv = nn.Conv2d(
14 in_channels, in_channels, kernel_size=3, stride=1, padding=1
15 )
16 self.cls_logits = nn.Conv2d(in_channels, num_anchors, kernel_size=1, stride=1)
17 self.bbox_pred = nn.Conv2d(
18 in_channels, num_anchors * 4, kernel_size=1, stride=1
19 )
20
21 for l in self.children():
22 torch.nn.init.normal_(l.weight, std=0.01)
23 torch.nn.init.constant_(l.bias, 0)
24
25 def forward(self, x):
26 # type: (List[Tensor])
27 logits = []
28 bbox_reg = []
29 for feature in x:
30 t = F.relu(self.conv(feature))
31 logits.append(self.cls_logits(t))
32 bbox_reg.append(self.bbox_pred(t))
33 return logits, bbox_reg
可以看到 self.cls_logits的输出是num_anchors 个。
如果是使用softmax来得到2k个score,这里还有一个坑是softmax的维度
"Number of labels must match number of predictions; " "e.g., if softmax axis == 1 and prediction shape is (N, C, H, W), " "label count (number of labels) must be N*H*W, " "with integer values in {0, 1, ..., C-1}.";
所以经常要在softmax前后进行reshape 把[1, 2x9, H, W] 变成 [1, 2, 9xH, W]。“腾空”出来一个维度以便softmax分类,之后再reshape回复原状。
接下来我们整体看一下RPN的pytorch实现。 由于我们不关心training的过程,为了代码的整洁,这里省略了 assign_targets_to_anchors和compute_loss 两个函数的代码。
这个代码的核心在于 filter_proposals 这个函数,相当于对proposals做一些后处理。比如去掉出了边界框的,去掉太小的proposals,然后根据NMS来再去掉一些。 这里有几个参数要注意:
- pre_nms_top_n. 在进行nms之前保留的proposals个数
- post_nms_top_n. nms之后保留的proposals个数
(某足球项目,nms还有decode_box 这里的bug和北京的同事联调了半个月才全部解决Orz.. 醉生梦死的经历。 这部分实现其实细节还挺多的,又没有统一的标准,很容易造成误差... 下次有机会讲一下。
然后forward函数就相当于某些框架中的(比如caffe)proposal layer.
1
2class RegionProposalNetwork(torch.nn.Module):
3 """
4 Implements Region Proposal Network (RPN).
5 Arguments:
6 anchor_generator (AnchorGenerator): module that generates the anchors for a set of feature
7 maps.
8 head (nn.Module): module that computes the objectness and regression deltas
9 fg_iou_thresh (float): minimum IoU between the anchor and the GT box so that they can be
10 considered as positive during training of the RPN.
11 bg_iou_thresh (float): maximum IoU between the anchor and the GT box so that they can be
12 considered as negative during training of the RPN.
13 batch_size_per_image (int): number of anchors that are sampled during training of the RPN
14 for computing the loss
15 positive_fraction (float): proportion of positive anchors in a mini-batch during training
16 of the RPN
17 pre_nms_top_n (Dict[int]): number of proposals to keep before applying NMS. It should
18 contain two fields: training and testing, to allow for different values depending
19 on training or evaluation
20 post_nms_top_n (Dict[int]): number of proposals to keep after applying NMS. It should
21 contain two fields: training and testing, to allow for different values depending
22 on training or evaluation
23 nms_thresh (float): NMS threshold used for postprocessing the RPN proposals
24 """
25 __annotations__ = {
26 'box_coder': det_utils.BoxCoder,
27 'proposal_matcher': det_utils.Matcher,
28 'fg_bg_sampler': det_utils.BalancedPositiveNegativeSampler,
29 'pre_nms_top_n': Dict[str, int],
30 'post_nms_top_n': Dict[str, int],
31 }
32
33 def __init__(self,
34 anchor_generator,
35 head,
36 #
37 fg_iou_thresh, bg_iou_thresh,
38 batch_size_per_image, positive_fraction,
39 #
40 pre_nms_top_n, post_nms_top_n, nms_thresh):
41 super(RegionProposalNetwork, self).__init__()
42 self.anchor_generator = anchor_generator
43 self.head = head
44 self.box_coder = det_utils.BoxCoder(weights=(1.0, 1.0, 1.0, 1.0))
45
46 # used during training
47 self.box_similarity = box_ops.box_iou
48
49 self.proposal_matcher = det_utils.Matcher(
50 fg_iou_thresh,
51 bg_iou_thresh,
52 allow_low_quality_matches=True,
53 )
54
55 self.fg_bg_sampler = det_utils.BalancedPositiveNegativeSampler(
56 batch_size_per_image, positive_fraction
57 )
58 # used during testing
59 self._pre_nms_top_n = pre_nms_top_n
60 self._post_nms_top_n = post_nms_top_n
61 self.nms_thresh = nms_thresh
62 self.min_size = 1e-3
63
64 def pre_nms_top_n(self):
65 if self.training:
66 return self._pre_nms_top_n['training']
67 return self._pre_nms_top_n['testing']
68
69 def post_nms_top_n(self):
70 if self.training:
71 return self._post_nms_top_n['training']
72 return self._post_nms_top_n['testing']
73
74 def assign_targets_to_anchors(self, anchors, targets):
75 # type: (List[Tensor], List[Dict[str, Tensor]])
76 pass
77 def _get_top_n_idx(self, objectness, num_anchors_per_level):
78 # type: (Tensor, List[int])
79 r = []
80 offset = 0
81 for ob in objectness.split(num_anchors_per_level, 1):
82 if torchvision._is_tracing():
83 num_anchors, pre_nms_top_n = _onnx_get_num_anchors_and_pre_nms_top_n(ob, self.pre_nms_top_n())
84 else:
85 num_anchors = ob.shape[1]
86 pre_nms_top_n = min(self.pre_nms_top_n(), num_anchors)
87 _, top_n_idx = ob.topk(pre_nms_top_n, dim=1)
88 r.append(top_n_idx + offset)
89 offset += num_anchors
90 return torch.cat(r, dim=1)
91
92 def filter_proposals(self, proposals, objectness, image_shapes, num_anchors_per_level):
93 # type: (Tensor, Tensor, List[Tuple[int, int]], List[int])
94 num_images = proposals.shape[0]
95 device = proposals.device
96 # do not backprop throught objectness
97 objectness = objectness.detach()
98 objectness = objectness.reshape(num_images, -1)
99
100 levels = [
101 torch.full((n,), idx, dtype=torch.int64, device=device)
102 for idx, n in enumerate(num_anchors_per_level)
103 ]
104 levels = torch.cat(levels, 0)
105 levels = levels.reshape(1, -1).expand_as(objectness)
106
107 # select top_n boxes independently per level before applying nms
108 top_n_idx = self._get_top_n_idx(objectness, num_anchors_per_level)
109
110 image_range = torch.arange(num_images, device=device)
111 batch_idx = image_range[:, None]
112
113 objectness = objectness[batch_idx, top_n_idx]
114 levels = levels[batch_idx, top_n_idx]
115 proposals = proposals[batch_idx, top_n_idx]
116
117 final_boxes = []
118 final_scores = []
119 for boxes, scores, lvl, img_shape in zip(proposals, objectness, levels, image_shapes):
120 boxes = box_ops.clip_boxes_to_image(boxes, img_shape)
121 keep = box_ops.remove_small_boxes(boxes, self.min_size)
122 boxes, scores, lvl = boxes[keep], scores[keep], lvl[keep]
123 # non-maximum suppression, independently done per level
124 keep = box_ops.batched_nms(boxes, scores, lvl, self.nms_thresh)
125 # keep only topk scoring predictions
126 keep = keep[:self.post_nms_top_n()]
127 boxes, scores = boxes[keep], scores[keep]
128 final_boxes.append(boxes)
129 final_scores.append(scores)
130 return final_boxes, final_scores
131
132 def compute_loss(self, objectness, pred_bbox_deltas, labels, regression_targets):
133 # type: (Tensor, Tensor, List[Tensor], List[Tensor])
134 """
135 Arguments:
136 objectness (Tensor)
137 pred_bbox_deltas (Tensor)
138 labels (List[Tensor])
139 regression_targets (List[Tensor])
140 Returns:
141 objectness_loss (Tensor)
142 box_loss (Tensor)
143 """
144
145 pass
146 def forward(self, images, features, targets=None):
147 # type: (ImageList, Dict[str, Tensor], Optional[List[Dict[str, Tensor]]])
148 """
149 Arguments:
150 images (ImageList): images for which we want to compute the predictions
151 features (List[Tensor]): features computed from the images that are
152 used for computing the predictions. Each tensor in the list
153 correspond to different feature levels
154 targets (List[Dict[Tensor]]): ground-truth boxes present in the image (optional).
155 If provided, each element in the dict should contain a field `boxes`,
156 with the locations of the ground-truth boxes.
157 Returns:
158 boxes (List[Tensor]): the predicted boxes from the RPN, one Tensor per
159 image.
160 losses (Dict[Tensor]): the losses for the model during training. During
161 testing, it is an empty dict.
162 """
163 # RPN uses all feature maps that are available
164 features = list(features.values())
165 objectness, pred_bbox_deltas = self.head(features)
166 anchors = self.anchor_generator(images, features)
167
168 num_images = len(anchors)
169 num_anchors_per_level_shape_tensors = [o[0].shape for o in objectness]
170 num_anchors_per_level = [s[0] * s[1] * s[2] for s in num_anchors_per_level_shape_tensors]
171 objectness, pred_bbox_deltas = \
172 concat_box_prediction_layers(objectness, pred_bbox_deltas)
173 # apply pred_bbox_deltas to anchors to obtain the decoded proposals
174 # note that we detach the deltas because Faster R-CNN do not backprop through
175 # the proposals
176 proposals = self.box_coder.decode(pred_bbox_deltas.detach(), anchors)
177 proposals = proposals.view(num_images, -1, 4)
178 boxes, scores = self.filter_proposals(proposals, objectness, images.image_sizes, num_anchors_per_level)
179
180 losses = {}
181 if self.training:
182 assert targets is not None
183 labels, matched_gt_boxes = self.assign_targets_to_anchors(anchors, targets)
184 regression_targets = self.box_coder.encode(matched_gt_boxes, anchors)
185 loss_objectness, loss_rpn_box_reg = self.compute_loss(
186 objectness, pred_bbox_deltas, labels, regression_targets)
187 losses = {
188 "loss_objectness": loss_objectness,
189 "loss_rpn_box_reg": loss_rpn_box_reg,
190 }
191 return boxes, losses
192
ROI Pooling和ROI Align Pooling
接下来介绍一下ROI Pooling,以及对它的改进 ROI Align Pooling
为什么需要ROI Pooling? 原因是在经过RPN网络后,得到的proposals的尺寸是不统一的。而CNN网络需要固定尺寸的输入。
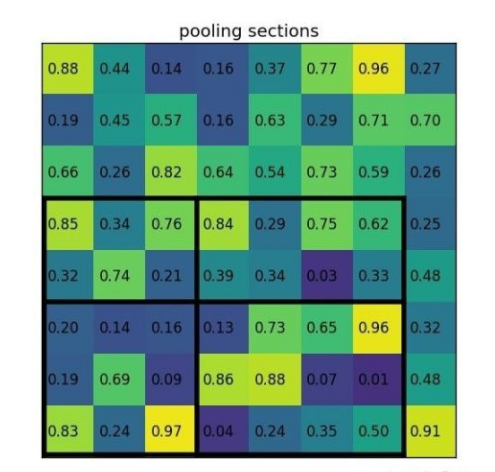
举个例子,上面88的的featrue map和7*5的proposal,希望得到2*2的输出。 但是没办法整除,roi pooling的做法是,直接取整,把7分成3,4两部分,把5分成2和3两部分。 然后在这四个区域做pooling,得到22的尺寸。
这部分torchvision的pytorch实现里面混合了mask rcnn还有其他关键点算法,不太直观,可以参考caffe的roi pooling layer.
可以看到里面ceil和floor 的取整操作。
1
2template <typename Dtype>
3void ROIPoolingLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
4 const vector<Blob<Dtype>*>& top) {
5 const Dtype* bottom_data = bottom[0]->cpu_data();
6 const Dtype* bottom_rois = bottom[1]->cpu_data();
7 // Number of ROIs
8 int num_rois = bottom[1]->num();
9 int batch_size = bottom[0]->num();
10 int top_count = top[0]->count();
11 Dtype* top_data = top[0]->mutable_cpu_data();
12 caffe_set(top_count, Dtype(-FLT_MAX), top_data);
13 int* argmax_data = max_idx_.mutable_cpu_data();
14 caffe_set(top_count, -1, argmax_data);
15
16 // For each ROI R = [batch_index x1 y1 x2 y2]: max pool over R
17 for (int n = 0; n < num_rois; ++n) {
18 int roi_batch_ind = bottom_rois[0];
19 int roi_start_w = round(bottom_rois[1] * spatial_scale_);
20 int roi_start_h = round(bottom_rois[2] * spatial_scale_);
21 int roi_end_w = round(bottom_rois[3] * spatial_scale_);
22 int roi_end_h = round(bottom_rois[4] * spatial_scale_);
23 CHECK_GE(roi_batch_ind, 0);
24 CHECK_LT(roi_batch_ind, batch_size);
25
26 int roi_height = max(roi_end_h - roi_start_h + 1, 1);
27 int roi_width = max(roi_end_w - roi_start_w + 1, 1);
28 const Dtype bin_size_h = static_cast<Dtype>(roi_height)
29 / static_cast<Dtype>(pooled_height_);
30 const Dtype bin_size_w = static_cast<Dtype>(roi_width)
31 / static_cast<Dtype>(pooled_width_);
32
33 const Dtype* batch_data = bottom_data + bottom[0]->offset(roi_batch_ind);
34
35 for (int c = 0; c < channels_; ++c) {
36 for (int ph = 0; ph < pooled_height_; ++ph) {
37 for (int pw = 0; pw < pooled_width_; ++pw) {
38 // Compute pooling region for this output unit:
39 // start (included) = floor(ph * roi_height / pooled_height_)
40 // end (excluded) = ceil((ph + 1) * roi_height / pooled_height_)
41 int hstart = static_cast<int>(floor(static_cast<Dtype>(ph)
42 * bin_size_h));
43 int wstart = static_cast<int>(floor(static_cast<Dtype>(pw)
44 * bin_size_w));
45 int hend = static_cast<int>(ceil(static_cast<Dtype>(ph + 1)
46 * bin_size_h));
47 int wend = static_cast<int>(ceil(static_cast<Dtype>(pw + 1)
48 * bin_size_w));
49
50 hstart = min(max(hstart + roi_start_h, 0), height_);
51 hend = min(max(hend + roi_start_h, 0), height_);
52 wstart = min(max(wstart + roi_start_w, 0), width_);
53 wend = min(max(wend + roi_start_w, 0), width_);
54
55 bool is_empty = (hend <= hstart) || (wend <= wstart);
56
57 const int pool_index = ph * pooled_width_ + pw;
58 if (is_empty) {
59 top_data[pool_index] = 0;
60 argmax_data[pool_index] = -1;
61 }
62
63 for (int h = hstart; h < hend; ++h) {
64 for (int w = wstart; w < wend; ++w) {
65 const int index = h * width_ + w;
66 if (batch_data[index] > top_data[pool_index]) {
67 top_data[pool_index] = batch_data[index];
68 argmax_data[pool_index] = index;
69 }
70 }
71 }
72 }
73 }
74 // Increment all data pointers by one channel
75 batch_data += bottom[0]->offset(0, 1);
76 top_data += top[0]->offset(0, 1);
77 argmax_data += max_idx_.offset(0, 1);
78 }
79 // Increment ROI data pointer
80 bottom_rois += bottom[1]->offset(1);
81 }
82}
83
84
85
这个办法简单粗暴,而且很容易意识到,这样取整对真实的信息产生了偏差。大物体可能还好说,小物体的话这个问题就会比较严重。
因此在Mask R-CNN 提出了一种改进办法,称之为"RoI Align Pooling".
思路是说,如果不能整除,那么不取整,而是通过插值等手段近似出那个不整的点的值。
代码可以参考caffe的GPU实现:
1
2template <typename T>
3__global__ void RoIAlignForwardKernel(
4 const int nthreads,
5 const T* bottom_data,
6 const T spatial_scale,
7 const bool position_sensitive,
8 const int channels,
9 const int height,
10 const int width,
11 const int pooled_height,
12 const int pooled_width,
13 const int sampling_ratio,
14 const int num_roi_per_image,
15 const T* bottom_rois,
16 T* top_data) {
17 CUDA_KERNEL_LOOP(index, nthreads) {
18 // (n, c, ph, pw) is an element in the pooled output
19 int pw = index % pooled_width;
20 int ph = (index / pooled_width) % pooled_height;
21 int c = (index / pooled_width / pooled_height) % channels;
22 int n = index / pooled_width / pooled_height / channels;
23
24// const T* offset_bottom_rois = bottom_rois + n * 5;
25 const T* offset_bottom_rois = bottom_rois + n * 4;
26 int roi_batch_ind = n / num_roi_per_image;
27
28 // Do not using rounding; this implementation detail is critical
29 T roi_start_w = offset_bottom_rois[0] * spatial_scale;
30 T roi_start_h = offset_bottom_rois[1] * spatial_scale;
31 T roi_end_w = offset_bottom_rois[2] * spatial_scale;
32 T roi_end_h = offset_bottom_rois[3] * spatial_scale;
33 // T roi_start_w = round(offset_bottom_rois[1] * spatial_scale);
34 // T roi_start_h = round(offset_bottom_rois[2] * spatial_scale);
35 // T roi_end_w = round(offset_bottom_rois[3] * spatial_scale);
36 // T roi_end_h = round(offset_bottom_rois[4] * spatial_scale);
37
38 // Force malformed ROIs to be 1x1
39 T roi_width = max(roi_end_w - roi_start_w, (T)1.);
40 T roi_height = max(roi_end_h - roi_start_h, (T)1.);
41 T bin_size_h = static_cast<T>(roi_height) / static_cast<T>(pooled_height);
42 T bin_size_w = static_cast<T>(roi_width) / static_cast<T>(pooled_width);
43
44 int c_unpooled = c;
45 int channels_unpooled = channels;
46 if (position_sensitive) {
47 c_unpooled = c * pooled_height * pooled_width + ph * pooled_width + pw;
48 channels_unpooled = channels * pooled_height * pooled_width;
49 }
50 const T* offset_bottom_data =
51 bottom_data + (roi_batch_ind * channels_unpooled + c_unpooled)
52 * height * width;
53
54 // We use roi_bin_grid to sample the grid and mimic integral
55 int roi_bin_grid_h = (sampling_ratio > 0)
56 ? sampling_ratio
57 : ceil(roi_height / pooled_height); // e.g., = 2
58 int roi_bin_grid_w =
59 (sampling_ratio > 0) ? sampling_ratio : ceil(roi_width / pooled_width);
60
61 // We do average (integral) pooling inside a bin
62 const T count = roi_bin_grid_h * roi_bin_grid_w; // e.g. = 4
63
64 T output_val = 0.;
65 for (int iy = 0; iy < roi_bin_grid_h; iy++) { // e.g., iy = 0, 1
66 const T y = roi_start_h + ph * bin_size_h +
67 static_cast<T>(iy + .5f) * bin_size_h /
68 static_cast<T>(roi_bin_grid_h); // e.g., 0.5, 1.5
69 for (int ix = 0; ix < roi_bin_grid_w; ix++) {
70 const T x = roi_start_w + pw * bin_size_w +
71 static_cast<T>(ix + .5f) * bin_size_w /
72 static_cast<T>(roi_bin_grid_w);
73
74 T val = bilinear_interpolate(
75 offset_bottom_data, height, width, y, x, index);
76 output_val += val;
77 }
78 }
79 output_val /= count;
80
81 top_data[index] = output_val;
82 }
83}
84
85
这里面有一个坑是,roi align layer有个参数叫num_roi_per_image
1
2message RoIAlignParameter {
3 optional uint32 pooled_h = 1 [default = 0];
4 optional uint32 pooled_w = 2 [default = 0];
5 optional float spatial_scale = 3 [default = 1];
6 optional int32 sample_ratio = 4 [default = -1];
7 optional bool position_sensitive = 5 [default = false];
8 optional uint32 num_roi_per_image = 6 [default = 300];
9}
10
11
然后这东西是有一个默认值300的。 因为在roialign之前的proposal layer的post_nms的值一般是300. 所以一般不会有什么影响。 但是如果nms之后的roi数量小于300,而num_roi_per_image又是默认300的话,就会把后面图片的roi分给第一张图,导致结果错误。
总结
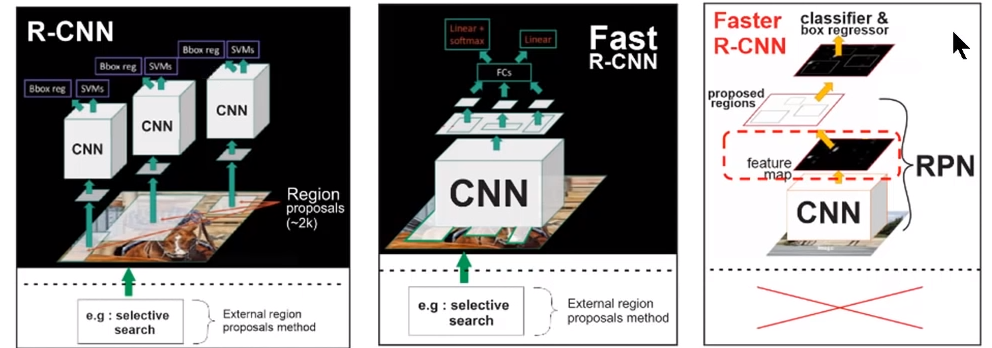
- R-CNN对图像选取若干提议区域,然后用卷积神经网络对每个提议区域做前向计算抽取特征,再用这些特征预测提议区域的类别和边界框。
- Fast R-CNN对R-CNN的一个主要改进在于只对整个图像做卷积神经网络的前向计算。它引入了兴趣区域池化层,从而令兴趣区域能够抽取出形状相同的特征。
- Faster R-CNN将Fast R-CNN中的选择性搜索替换成区域提议网络,从而减少提议区域的生成数量,并保证目标检测的精度。
- Mask R-CNN在Faster R-CNN基础上引入一个全卷积网络,从而借助目标的像素级位置进一步提升目标检测的精度。