resnet 学习笔记
背景
基于Conv的方法在某年的ImageNet比赛上又重新被人想起之后,大家发现网络堆叠得越深,似乎在cv的各个任务上表现的越好。
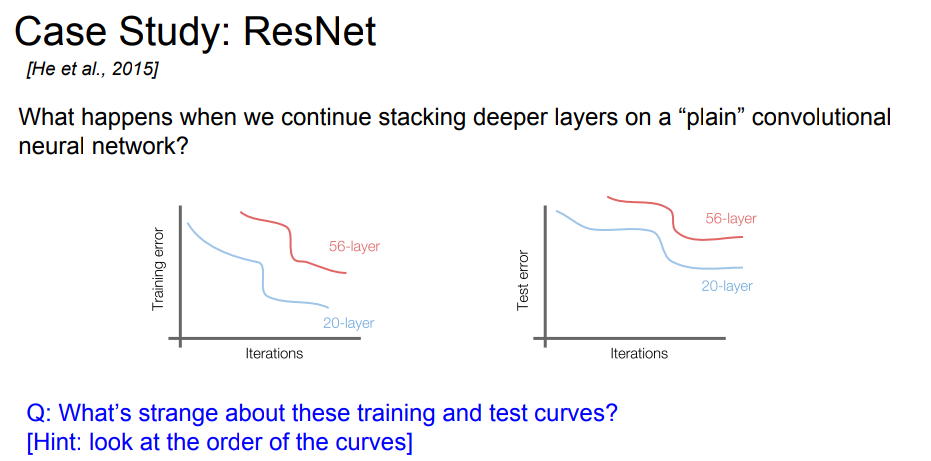
然而事情当然没有无脑退跌深度那么简单,人们发现,当网络深到一定程度时,结果还不如浅一些的网络结构。
可能第一反应是,网路那么深,多了那么多参数,有那么多数据吗? overfit了吧
然而情况没有那么简单。如果只是单纯得overfit,那么应该只有test error很高才对。然而现在的情况是training error也很高。
那这是怎么回事呢? Resnet的团队认为,是因为深层的网络在训练的时候很难收敛。
这个想法是有依据的,因为我们可以通过构造一个较深的网络结构,使得后面的layer学成一个"identity mapping"的函数。这样training error和test error应该至少和一个浅层网络的结果一样好才对。
那么问题很可能就出在,深层的网络没办法学到这样的函数。
基于这样的想法,resnet团队提出了一种新的结构,称之为"skip connection",来验证该假设。
resnet网络结构
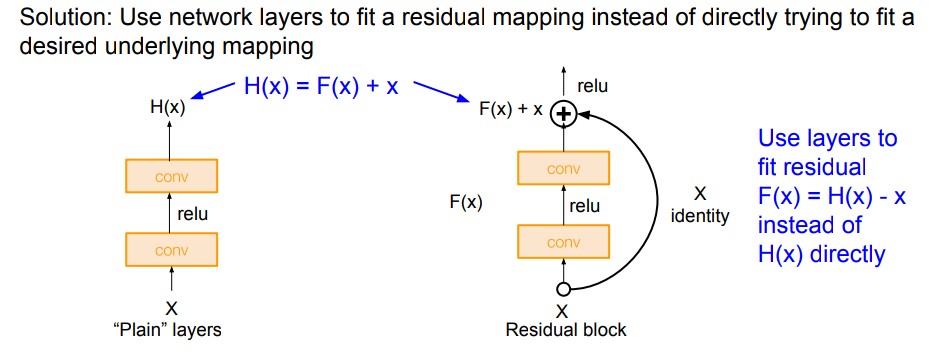
我们可以看到,该结构把原来网络要学的H(x),变成了F(X)+X的形势。 因此网络只需要学习F(X),也就是在 "identity mapping"上学习一个偏移。
实验表明,这种结构对于深层的网络是非常有效的,因为这种结构将默认设置变为了"identity mapping",整个网络变得更加容易收敛。
resnet也成了目前工业界各种网络结构的标准backbone
resnet 结构的caffe prototxt
放了resnet50的部分结构,截止到第一个resnet block
1
2name: "ResNet-50"
3input: "data"
4input_dim: 1
5input_dim: 3
6input_dim: 224
7input_dim: 224
8
9layer {
10 bottom: "data"
11 top: "conv1"
12 name: "conv1"
13 type: "Convolution"
14 convolution_param {
15 num_output: 64
16 kernel_size: 7
17 pad: 3
18 stride: 2
19 }
20}
21
22layer {
23 bottom: "conv1"
24 top: "conv1"
25 name: "bn_conv1"
26 type: "BatchNorm"
27 batch_norm_param {
28 use_global_stats: true
29 }
30}
31
32layer {
33 bottom: "conv1"
34 top: "conv1"
35 name: "scale_conv1"
36 type: "Scale"
37 scale_param {
38 bias_term: true
39 }
40}
41
42layer {
43 bottom: "conv1"
44 top: "conv1"
45 name: "conv1_relu"
46 type: "ReLU"
47}
48
49layer {
50 bottom: "conv1"
51 top: "pool1"
52 name: "pool1"
53 type: "Pooling"
54 pooling_param {
55 kernel_size: 3
56 stride: 2
57 pool: MAX
58 }
59}
60
61layer {
62 bottom: "pool1"
63 top: "res2a_branch1"
64 name: "res2a_branch1"
65 type: "Convolution"
66 convolution_param {
67 num_output: 256
68 kernel_size: 1
69 pad: 0
70 stride: 1
71 bias_term: false
72 }
73}
74
75layer {
76 bottom: "res2a_branch1"
77 top: "res2a_branch1"
78 name: "bn2a_branch1"
79 type: "BatchNorm"
80 batch_norm_param {
81 use_global_stats: true
82 }
83}
84
85layer {
86 bottom: "res2a_branch1"
87 top: "res2a_branch1"
88 name: "scale2a_branch1"
89 type: "Scale"
90 scale_param {
91 bias_term: true
92 }
93}
94
95layer {
96 bottom: "pool1"
97 top: "res2a_branch2a"
98 name: "res2a_branch2a"
99 type: "Convolution"
100 convolution_param {
101 num_output: 64
102 kernel_size: 1
103 pad: 0
104 stride: 1
105 bias_term: false
106 }
107}
108
109layer {
110 bottom: "res2a_branch2a"
111 top: "res2a_branch2a"
112 name: "bn2a_branch2a"
113 type: "BatchNorm"
114 batch_norm_param {
115 use_global_stats: true
116 }
117}
118
119layer {
120 bottom: "res2a_branch2a"
121 top: "res2a_branch2a"
122 name: "scale2a_branch2a"
123 type: "Scale"
124 scale_param {
125 bias_term: true
126 }
127}
128
129layer {
130 bottom: "res2a_branch2a"
131 top: "res2a_branch2a"
132 name: "res2a_branch2a_relu"
133 type: "ReLU"
134}
135
136layer {
137 bottom: "res2a_branch2a"
138 top: "res2a_branch2b"
139 name: "res2a_branch2b"
140 type: "Convolution"
141 convolution_param {
142 num_output: 64
143 kernel_size: 3
144 pad: 1
145 stride: 1
146 bias_term: false
147 }
148}
149
150layer {
151 bottom: "res2a_branch2b"
152 top: "res2a_branch2b"
153 name: "bn2a_branch2b"
154 type: "BatchNorm"
155 batch_norm_param {
156 use_global_stats: true
157 }
158}
159
160layer {
161 bottom: "res2a_branch2b"
162 top: "res2a_branch2b"
163 name: "scale2a_branch2b"
164 type: "Scale"
165 scale_param {
166 bias_term: true
167 }
168}
169
170layer {
171 bottom: "res2a_branch2b"
172 top: "res2a_branch2b"
173 name: "res2a_branch2b_relu"
174 type: "ReLU"
175}
176
177layer {
178 bottom: "res2a_branch2b"
179 top: "res2a_branch2c"
180 name: "res2a_branch2c"
181 type: "Convolution"
182 convolution_param {
183 num_output: 256
184 kernel_size: 1
185 pad: 0
186 stride: 1
187 bias_term: false
188 }
189}
190
191layer {
192 bottom: "res2a_branch2c"
193 top: "res2a_branch2c"
194 name: "bn2a_branch2c"
195 type: "BatchNorm"
196 batch_norm_param {
197 use_global_stats: true
198 }
199}
200
201layer {
202 bottom: "res2a_branch2c"
203 top: "res2a_branch2c"
204 name: "scale2a_branch2c"
205 type: "Scale"
206 scale_param {
207 bias_term: true
208 }
209}
210
211layer {
212 bottom: "res2a_branch1"
213 bottom: "res2a_branch2c"
214 top: "res2a"
215 name: "res2a"
216 type: "Eltwise"
217}
218
219layer {
220 bottom: "res2a"
221 top: "res2a"
222 name: "res2a_relu"
223 type: "ReLU"
224}
可视化的结构为:
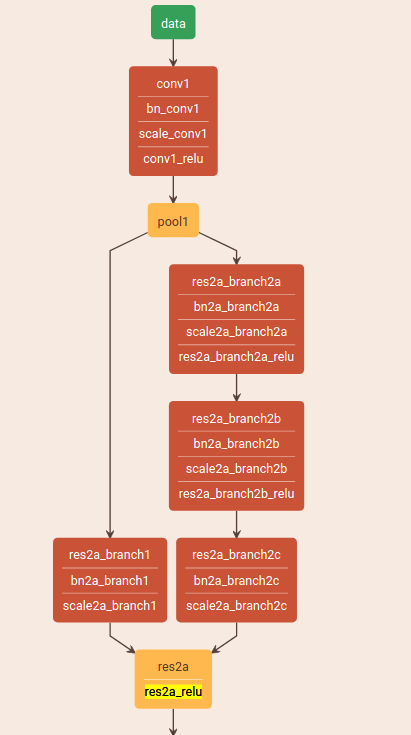
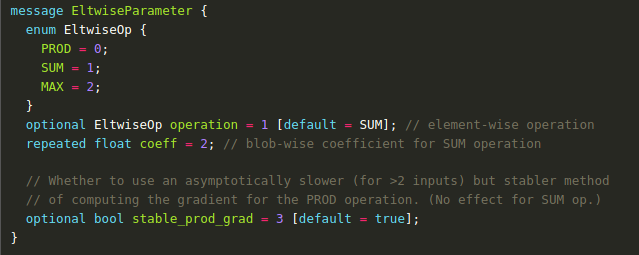
重点要关注的是 res2a 这个layer,把两个分支的结果直接加在了一起。 eltwise的layer是按照元素操作的,支持乘积,相加,或者取最大值,默认是相加。 可以参考caffe的proto文件
resnet 结构的pytorch实现
可以直接参考torch vision的代码
因为pytorch是通过代码来定义网络结果,不如caffe那么直观,因此就只放了resnet block的部分,代码非常容易看懂,就不解释了。 完整的代码可以参考 torchvision.models.resnet
1
2class BasicBlock(nn.Module):
3 expansion = 1
4
5 def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
6 base_width=64, dilation=1, norm_layer=None):
7 super(BasicBlock, self).__init__()
8 if norm_layer is None:
9 norm_layer = nn.BatchNorm2d
10 if groups != 1 or base_width != 64:
11 raise ValueError('BasicBlock only supports groups=1 and base_width=64')
12 if dilation > 1:
13 raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
14 # Both self.conv1 and self.downsample layers downsample the input when stride != 1
15 self.conv1 = conv3x3(inplanes, planes, stride)
16 self.bn1 = norm_layer(planes)
17 self.relu = nn.ReLU(inplace=True)
18 self.conv2 = conv3x3(planes, planes)
19 self.bn2 = norm_layer(planes)
20 self.downsample = downsample
21 self.stride = stride
22
23 def forward(self, x):
24 identity = x
25
26 out = self.conv1(x)
27 out = self.bn1(out)
28 out = self.relu(out)
29
30 out = self.conv2(out)
31 out = self.bn2(out)
32
33 if self.downsample is not None:
34 identity = self.downsample(x)
35
36 out += identity
37 out = self.relu(out)
38
39 return out
resnet的变种
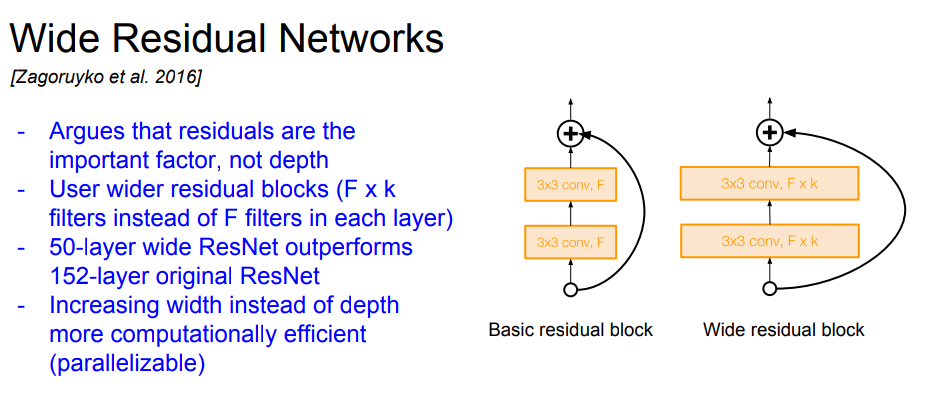
wide resnet
强调起作用(对于更低的error)的是resnet block,而不是更深的网络结构。 在每一个resnet block中,使用更多的filter来达到和更深的resnet相媲美的结果。
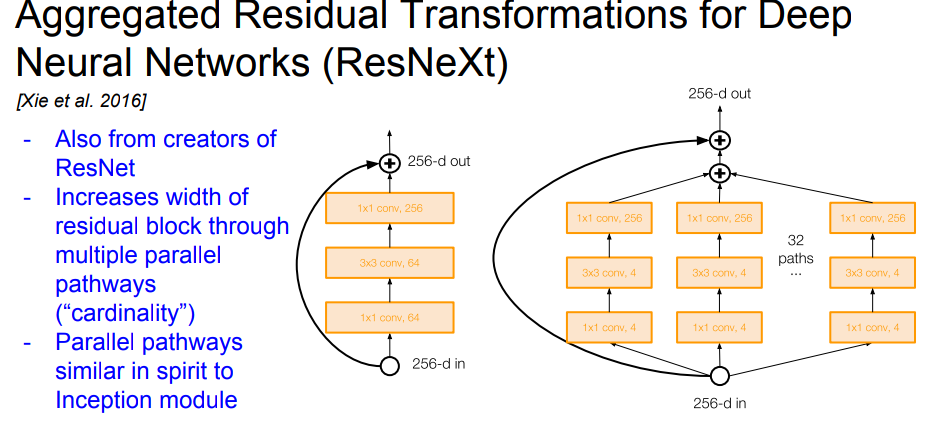
ResNeXt
收到inception网络的启发,使用更多的路径。